

Esta semana quería comentaros al respecto de algo que ha pasado y que, a priori, parece otra noticia técnica más sobre un modelo de IA chino. Pero que tiene varias capas y, sinceramente, creo que va a marcar un antes y un después.
Hace nueve días, Jensen Huang, el CEO de NVIDIA, dijo en un podcast algo bastante curioso. Y exactamente nueve días después.. ocurrió.
¿Os acordáis del artículo de la semana pasada en el que decíamos que la carrera por la AGI eran en realidad dos carreras? Occidente reducido a tres (Anthropic, OpenAI y Google DeepMind) y China jugando en su propia liga. Pues esa otra liga acaba de cruzarse con la nuestra.
Vamos por partes.
La advertencia que se cumplió en nueve días
El 15 de abril, Jensen Huang se sentó en el podcast de Dwarkesh Patel. La conversación fue larga, pero hay un momento que merece la pena rescatar palabra por palabra. Refiriéndose a DeepSeek y a la posibilidad de que la empresa china optimizara sus modelos para correr sobre chips Huawei en lugar del hardware americano, Huang advirtió que sería “a horrible outcome for our nation” (cita textual).
Vamos, que el CEO de la compañía más valiosa del mundo, valorada cerca de los 5 billones de dólares, estaba advirtiendo en directo de algo bastante específico: no de que China desarrollara IA, ni de que DeepSeek lanzara más modelos, sino del momento concreto en el que un modelo chino frontier se lanzara primero corriendo sobre silicio chino.
Nueve días.
Eso es lo que tardó el mundo en darle la razón.
El golpe del 24 de abril
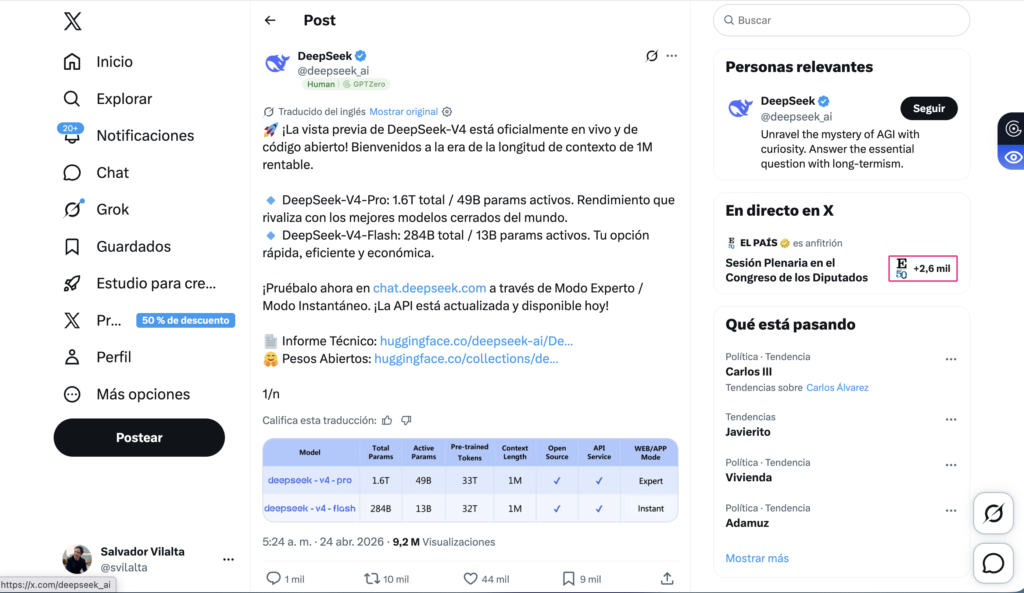
El pasado viernes 24 de abril, DeepSeek liberó la preview de su serie V4. Dos modelos open-source con licencia MIT, subidos a Hugging Face, con API y app disponibles el mismo día. Para los que vivimos esto cada día, fue uno de esos momentos en los que tienes que parar lo que estás haciendo y mirarlo dos veces.
DeepSeek-V4-Pro tiene 1,6 billones de parámetros totales con 49 mil millones activos en cada inferencia, en arquitectura Mixture-of-Experts. DeepSeek-V4-Flash, su hermano pequeño, tiene 284 mil millones totales y 13 mil millones activos. Ambos vienen con un contexto de un millón de tokens por defecto y un output máximo de 384 mil tokens. Y aquí viene el matiz que casi nadie ha contado bien: ese millón de tokens no es un add-on. No es un parche montado por encima de la arquitectura, sino que es la arquitectura desde el primer día construida alrededor del millón de tokens como contexto natural.
Eso lo cambia todo.
La arquitectura combina dos mecanismos llamados Compressed Sparse Attention y Heavily Compressed Attention. No quiero perderos en lo técnico, pero la idea importante es que reducen el cache KV en un factor de 128, dejándolo en menos del 1% del tamaño original. ¿Y qué significa eso en términos prácticos? Pues que para un contexto de un millón de tokens, V4-Pro necesita solo el 27% de los FLOPs y el 10% del cache KV que necesitaba la versión anterior. Es decir, el modelo va más fino, gasta mucho menos y maneja contextos brutales sin despeinarse.
¿Y dónde corre todo esto? Aquí es donde la historia se pone interesante.
Adiós a CUDA (o casi)
V4 es el primer modelo de DeepSeek diseñado formalmente para los chips Huawei Ascend 950. La inferencia de ambos modelos puede correr sobre Huawei y, además, V4-Flash presuntamente fue entrenado entero sobre silicio chino. El grande, V4-Pro, es probable que se entrenara en parte sobre NVIDIA, pero el mensaje que importa va por otro lado: la dependencia ya no es total.
Eso no es solo una historia de chips, es una historia de software.
NVIDIA lleva veinte años construyendo CUDA, su lenguaje de programación. Cuando hablamos de IA, hablamos de CUDA; cuando un gobierno financia infraestructura de IA, compra hardware NVIDIA porque el software que existe está pensado para CUDA. Es una de esas trampas perfectas en las que el incumbente gana porque su producto es bueno y, además, porque el ecosistema entero se ha construido alrededor de él.
V4 corre sobre el stack CANN de Huawei, con el kernel alineado con los NPUs Ascend en lugar de las GPUs NVIDIA. Y funciona. No solo funciona en una demo, sino en producción servida vía API. Cuando los expertos hablan de “test real de salida del ecosistema CUDA”, están hablando exactamente de esto.
¿Os acordáis cuando hablamos de Jensen Huang en el GTC 2026 con su chaqueta de cuero, anunciando Vera Rubin y Kyber durante casi tres horas y dejándonos a todos sin palabras? Pues una de las cosas que no estaba en su keynote, lógicamente, era el escenario que se acaba de materializar nueve días después de su aparición en Dwarkesh.
Y ahora, los números que duelen
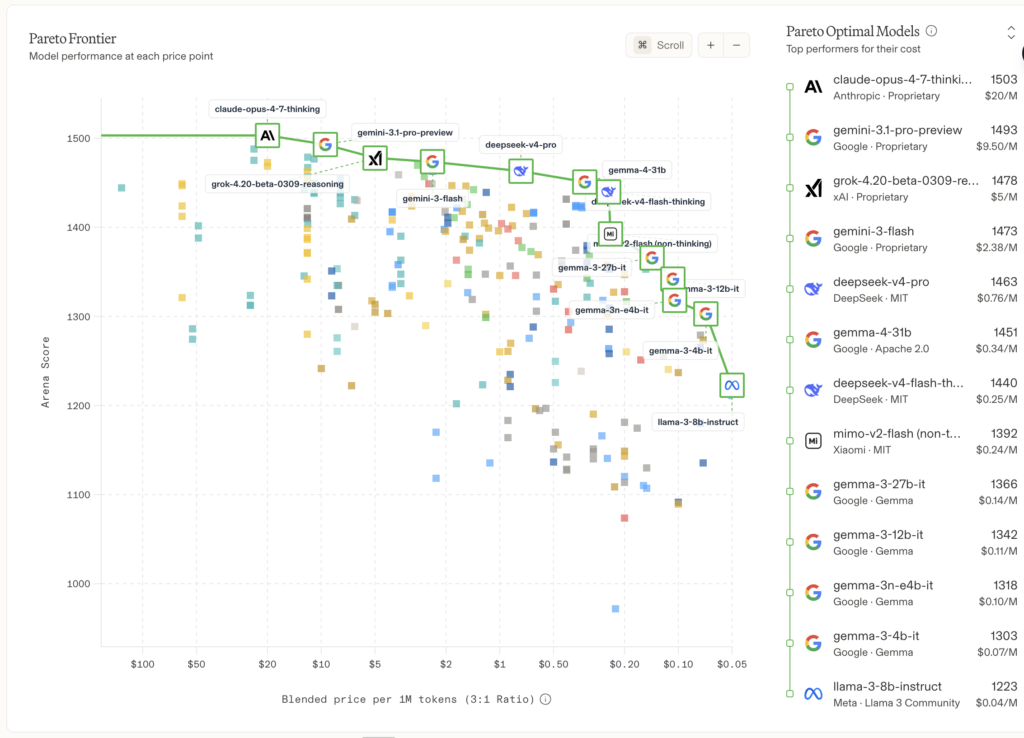
Vamos al bolsillo, que es donde más se nota. DeepSeek V4-Pro cobra 3,48 dólares por cada millón de tokens de output, mientras que Claude Opus 4.7 (Anthropic) cobra 25 dólares por la misma cantidad y GPT-5.5 (OpenAI) cobra 30. Una tarea que te costaría 35 dólares con GPT-5.5 te cuesta 5,22 con DeepSeek. Reducción del 85%.
Y si bajas a V4-Flash, el modelo más pequeño, el output cuesta 0,28 dólares por cada millón de tokens. Tu calculadora no está rota, no.
¿Y qué saca este modelo en benchmarks? Pues V4-Pro saca un 3.206 en Codeforces, lo que se traduce en nivel Grandmaster, el más alto. GPT-5.4 saca 3.168. Claude Opus ni siquiera ha reportado oficialmente su rating, lo cual ya os dice algo sobre cómo está el patio. En tareas analíticas, V4 se queda a 0,2 puntos de Opus 4.7 en algunos benchmarks. En coding agéntico, la cosa cambia y Claude sigue sacando ventaja por su filosofía de “targeted patches”, que es entender lo que un codebase ya hace y cambiar solo lo mínimo. Pero en analítica pura y síntesis de fuentes de datos, DeepSeek lidera.
A priori, si me dijeran “tienes que elegir entre pagar uno o seis”, la pregunta tiene una sola respuesta. Y es por eso que esto importa tanto, ¿no os parece?
El contraataque ya está en marcha
Anthropic y OpenAI no se han quedado quietos. De hecho, las dos empresas han acusado a DeepSeek de “destilar” ilegalmente capacidades de sus modelos. La distillation, para los que no estáis metidos en lo técnico, es una técnica en la que un modelo más pequeño aprende imitando las salidas de uno más grande; es legal cuando se hace con permiso y es problemática cuando se hace sin él.
¿Tienen razón? Es difícil saberlo. Lo que sí parece claro es que la batalla legal y geopolítica no ha hecho más que empezar. Los export controls americanos sobre chips se van a tensar, las acusaciones de robo de IP van a seguir y los gobiernos europeos van a tener que decidir si una IA china ultrabarata es un riesgo o una oportunidad.
Curiosamente, la reacción de Wall Street ha sido bastante más muteada que cuando salió DeepSeek R1 hace un año. ¿Os acordáis del 27 de enero del 2025? Aquel día NVIDIA cayó un 18% en una sola sesión y el mercado se asustó al darse cuenta de que la IA china era competitiva y mucho más barata. Esta vez, en cambio, los analistas dicen que el mercado ya ha descontado que esto iba a pasar. “Las tendencias no producen titulares como los hacen los shocks”, como decía un analista en Raconteur (cita textual).
Yo, en cambio, no estoy tan seguro de que esto sea solo una tendencia.
Lo que yo creo
Lo primero es que el precio rompe la economía de la IA empresarial. Cuando una herramienta cuesta 1/6 que su rival y va casi al mismo nivel, las decisiones de compra cambian; y cuando hablamos de empresas que están integrando IA en cada flujo, cada email, cada análisis, cada informe.. la diferencia de coste entre 5 dólares y 35 dólares por tarea se multiplica por miles. La presión sobre los márgenes de Anthropic y OpenAI va a ser realmente significativa.
Lo segundo es que el ecosistema CUDA tiene grieta. Después de veinte años construyendo el lenguaje por defecto del AI development, ahora aparece un modelo serio que no lo necesita. No digo que CUDA muera mañana, sino que la grieta es real y que, una vez que se demuestra que el camino alternativo funciona, otros lo recorren. La paradoja es bastante curiosa: los export controls americanos sobre chips, que estaban diseñados para frenar a China, han acabado acelerando la creación de un stack de IA chino independiente.
Y lo tercero, que para mí es lo más importante, es que las dos carreras de las que hablaba la semana pasada acaban de cruzarse. La liga occidental (Anthropic, OpenAI, Google DeepMind) y la liga china (DeepSeek, Qwen, Kimi) ya no son universos paralelos. DeepSeek V4, con un sexto del precio y open source, no juega solo en su propia liga: viene a competir directamente en la nuestra. La carrera, que parecía a tres, ahora es de facto a cuatro. Y los que se han quedado atrás, Meta y xAI, pueden tomar nota: el ticket de entrada no es necesariamente más cómputo NVIDIA, a veces es saber renunciar al ecosistema dominante.
Si tienes una empresa que ya está usando IA, mira los números, en serio. Hacer una prueba con DeepSeek V4 te puede ahorrar miles al mes; los modelos están en Hugging Face, son MIT, la API funciona y la calidad está cerca de lo mejor que tienes hoy.
Si lideras tecnología, lo que ha pasado esta semana no es una noticia más. Es la primera vez que el monopolio de facto del software de IA tiene una alternativa real. CANN no va a sustituir a CUDA mañana, pero ya no es un experimento de laboratorio: es producción.
Y si te interesa la geopolítica.. pues bienvenido al nuevo capítulo. La advertencia de Jensen Huang del 15 de abril ya está obsoleta. La pregunta ya no es si va a pasar, sino qué hacemos ahora que ha pasado.
Llegamos justo a tiempo a la fiesta donde dijimos que solo había tres invitados..
Déjame tus comentarios, me encantará leerte.
¡Buena semana!


