

This week I wanted to comment on something that has happened and that, a priori, seems like just another technical news about a Chinese AI model. But it has several layers, and honestly, I think it will mark a before-and-after.
Nine days ago, Jensen Huang, the CEO of NVIDIA, said in a podcast something rather curious. And exactly nine days later… it happened.
Remember last week’s last week’s article where we said that the AGI race was actually two races? The West has been reduced to three (Anthropic, OpenAI, and Google DeepMind), and China is playing in its own league. Well, that other league has just crossed ours.
Let’s take it one step at a time.
The warning that came true in nine days
On April 15, Jensen Huang sat down on Dwarkesh Patel’s podcast. The conversation was long, but there is one moment worth rescuing word for word. Referring to DeepSeek and the possibility that the Chinese company could optimize its models to run on Huawei chips rather than American hardware, Huang warned that it would be “a horrible outcome for our nation” (quote).
Come on, the CEO of the world’s most valuable company, valued at close to $5 trillion, was warning live of something quite specific: not of China developing AI, not of DeepSeek launching more models, but of the specific moment when a Chinese frontier model would first be launched running on Chinese silicon.
Nine days.
That’s how long it took for the world to agree with him.
The April 24 coup
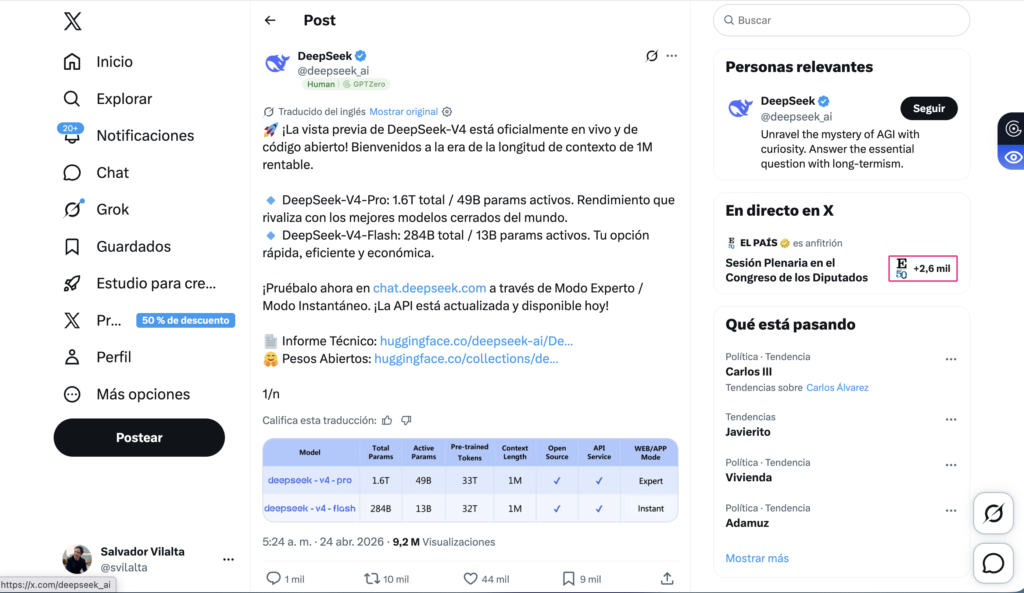
Last Friday, April 24, DeepSeek released the preview of its V4 series. preview of its V4 series. Two MIT-licensed open-source models, uploaded to Hugging Face, with API and app available the same day. For those of us who live this every day, it was one of those moments when you have to stop what you are doing and look twice.
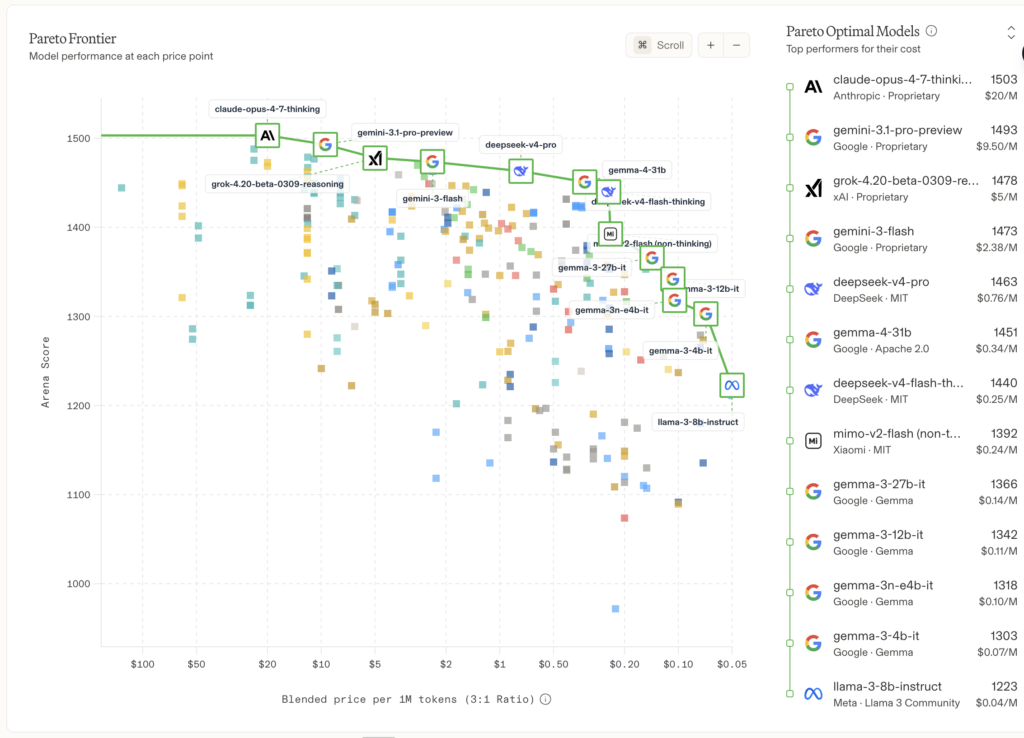
DeepSeek-V4-Pro has 1.6 trillion total parameters with 49 billion active in each inference, in a Mixture-of-Experts architecture. DeepSeek-V4-Flash, its little brother, has 284 billion total parameters and 13 billion active parameters. Both come with a context of one million tokens by default and a maximum output of 384 thousand tokens. And here comes the nuance that almost no one has counted right: that million tokens is not an add-on. It is not a patch mounted on top of the architecture, but it is the architecture from day one, built around the million tokens as a natural context.
That changes everything.
The architecture combines two mechanisms called Compressed Sparse Attention and Heavily Compressed Attention. I don’t want to get lost in the technical stuff, but the important idea is that they reduce the KV cache by a factor of 128, leaving it at less than 1% of the original size. And what does that mean in practical terms? Well, for a context of one million tokens, V4-Pro requires only 27% of the FLOPs and 10% of the KV cache cache that the previous version required. In other words, the model is much thinner, spends much less and handles brutal contexts without breaking a sweat.
And where does it all run? This is where the story gets interesting.
Goodbye to CUDA (or almost)
V4 is the first DeepSeek model formally designed for the Huawei Ascend 950 chips. Huawei Ascend 950 chips. The inference of both models may run on Huawei, and, in addition, V4-Flash was allegedly trained entirely on Chinese silicon. The big one, V4-Pro, is likely to be trained partly on NVIDIA, but the message that matters goes the other way: the dependency is no longer total.
That’s not just a chip story, it’s a software story.
NVIDIA has been building CUDA, its programming language, for twenty years. When we talk about AI, we talk about CUDA; when a government funds AI infrastructure, it buys NVIDIA hardware because the software out there is built for CUDA. It’s one of those perfect traps where the incumbent wins because their product is good, and also because the entire ecosystem is built around it.
V4 runs on Huawei’s CANN stack from Huaweistack, with the kernel aligned with Ascend NPUs instead of NVIDIA GPUs. And it works. It works not only in a demo, but in production, served via API. When experts talk about “real output test of the CUDA ecosystem”, they are talking about exactly this.
Do you remember when we talked about Jensen Huang at the GTC 2026 with his leather jacket, announcing Vera Rubin and Kyber for almost three hours, and leaving us all speechless? Well, one of the things that was not in his keynote, logically, was the scenario that just materialized nine days after his appearance at Dwarkesh.
And now, the numbers that hurt
Let’s get down to the pocket, which is where it’s most noticeable. DeepSeek V4-Pro charges 3.48 per million output tokens, while Claude Opus 4.7 (Anthropic) charges $25 per million output tokens. while Claude Opus 4.7 (Anthropic) charges $25 for the same amount, and GPT-5.5 (OpenAI) charges $30. A task that would cost you $35 with GPT-5.5 costs you $5.22 with DeepSeek. 85% reduction.
And if you go down to V4-Flash, the smallest model, the output costs $0.28 per million tokens. Your calculator is not broken, no.
And what does this model get in benchmarks? Well, V4-Pro scores a 3,206 in Codeforces, which translates to Grandmaster level, the highest. GPT-5.4 scores 3.168. Claude Opus hasn’t even officially reported his rating, which tells you something about the state of the game. In analytical tasks, V4 is 0.2 points behind Opus 4.7 in some benchmarks. In agentic coding, things are different, and Claude is still ahead because of its “targeted patches” philosophy, which is to understand what a codebase already does and change only the minimum. But in pure analytics and data source synthesis, DeepSeek leads.
A priori, if I were told “you have to choose between paying one or six”, the question has only one answer. And that’s why this matters so much, don’t you think?
The counterattack is already underway
Anthropic and OpenAI have not stood still. In fact, the two companies have accused DeepSeek of illegally “distilling” capabilities from their models. Distillation, for those of you not into the technical stuff, is a technique in which a smaller model learns by mimicking the outputs of a larger one; it is legal when done with permission and problematic when done without.
Are they right? It is hard to say. What does seem clear is that the legal and geopolitical battle is just beginning. American export controls on chips will tighten, accusations of IP theft will follow, and European governments will have to decide whether ultra-cheap Chinese AI is a risk or an opportunity.
Interestingly, Wall Street’s reaction has been rather more muted. much more muted than when DeepSeek R1 came out a year ago. than when DeepSeek R1 came out a year ago – remember January 27, 2025? That day, NVIDIA dropped 18% in a single session, and the market panicked as it realized that Chinese AI was competitive and much cheaper. This time, by contrast, analysts say the market has already discounted that this was going to happen. “Trends don’t produce headlines the way shocks do,” as one analyst in Raconteur put it (quote).
I, on the other hand, am not so sure that this is just a trend.
What I believe
The first thing is that price breaks the economics of enterprise AI. When a tool costs 1/6th that of its rival and goes to about the same level, buying decisions change; and when we’re talking about companies that are integrating AI into every flow, every email, every analysis, every report… the cost difference between $5 and $35 per task is multiplied by thousands. The pressure on the margins of Anthropic and OpenAI is going to be really significant.
The second thing is that the CUDA ecosystem is cracking. After twenty years of building the default language for AI development, a serious model comes along that doesn’t need it. I’m not saying that CUDA will die tomorrow, but that the crack is real and that, once the alternative path is proven to work, others will take it. The paradox is rather curious: American export controls on chips, designed to hold China back, have ended up accelerating the development of an independent Chinese AI stack.
And the third thing, which for me is the most important, is that the two careers I was talking about last week have just intersected. The Western league (Anthropic, OpenAI, Google DeepMind) and the Chinese league (DeepSeek, Qwen, Kimi) are no longer parallel universes. DeepSeek V4, with a sixth of the price and open source, does not play alone in its own league: it comes to compete directly in ours. The race, which seemed to be a three-way race, is now de facto a four-way race. And those who have been left behind, Meta and xAI, can take note: the entry ticket is not necessarily more NVIDIA compute; sometimes it is knowing how to give up the dominant ecosystem.
If you have a company that is already using AI, look at the numbers, seriously. Running a test with DeepSeek V4 can save you thousands a month; the models are in Hugging Face, they’re MIT, the API works, and the quality is close to the best you have today.
If you lead technology, what happened this week is not just another news story. It’s the first time the de facto monopoly in AI software has a real alternative. CANN isn’t going to replace CUDA tomorrow, but it’s no longer a lab experiment: it’s production.
And if you are interested in geopolitics… welcome to the new chapter. Jensen Huang’s warning of April 15 is now obsolete. The question is no longer whether it will happen, but what do we do now that it has happened.
We arrived just in time for the party where we said there were only three guests….
Leave me your comments, I’d love to read them.
Have a good week!


