

Imagine that the AI stops simply answering “What’s next?” and starts thinking, “What would happen if I move this object there?”. That shift in focus from textual prediction to physical simulation is one of the most interesting twists in the race toward Artificial General Intelligence (AGI).
Until now, the leading role has been played by large language models (LLMs), trained to generate fluent and meaningful text. But a new line of research is gaining ground: world models, systems designed not to write, but to imagine, simulate, and act in virtual environments.
This approach is not new to those of us who have been following the evolution of AI closely. In a previous article, I explored how
Both proposals point in the same direction: if language models have taught machines to read and write, world models seek to teach them to see, act, and learn from their environment. The combination of both routes could, at last, bring us closer to an artificial intelligence with an understanding closer to that of humans.
Language vs. the world: two different routes to intelligence
On the one hand, language models (LLMs) learn from large volumes of text: they predict the “next word”, generate responses, write, and translate. But their knowledge of the physical world is indirect: they have read about it, but have not “lived” it.
On the other hand, a world model focuses on simulating physical environments: objects, light, motion, interaction, so that the AI not only “talks” about the world, but can “see” it, “touch” its consequences, and plan within it. The company World Labs, co-founded by AI pioneer Fei-Fei Li, has just launched its first commercial product, Marble, which goes in this direction.

Key differences between an LLM and a model world
Let us now look at the differences between the two approaches:
Knowledge base: LLMs learn from text; world models from sensors, images, simulations.
Prediction objective: LLMs predict words; world models predict states of an environment, its physical or spatial evolution.
Embodiment: While the former “talk” about actions, the latter allow simulating actions (and experiences) in a virtual environment before performing them.
Modality / perception: LLMs operate mostly in text; world models are multimodal (vision, audio, possibly physical sensors) and build a “mental model” of space.
Marble's approach: editing, exporting and interoperability
Marble goes beyond a demo: it accepts text, images, video, and even 3D sketches as input to generate virtual worlds that can be edited and exported to standard tools,for example:
-
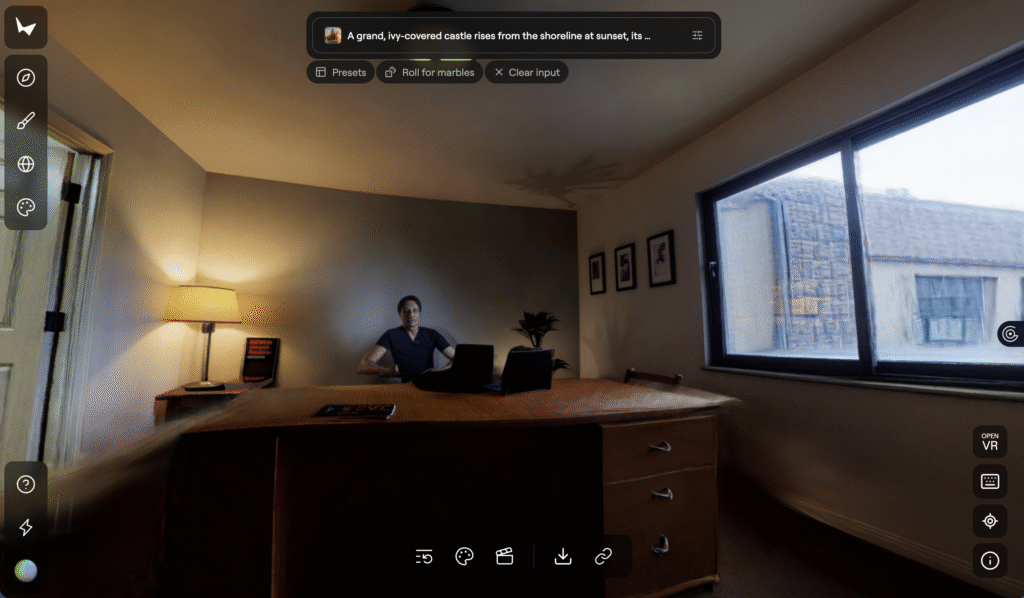
Take a simple picture of a room → Marble infers and generates the rest of the scene in 3D. Here below you can see a quick test I did with this environment.
-
Edit: change tables to benches, modify objects and transform the visual style without redoing from scratch.
-
Export: as “Gaussian splats”, 3D meshes, video; which makes it easy to integrate it in development pipelines of video games, VFX, industrial simulation.
For those who work in process automation, this touches a crucial point: it opens the possibility of building simulated worlds for automated agents (robots, autonomous processes) to learn in a safe, fast, and scalable way.
Applications and potential for AGI
Why is this approach generating so much interest? Because it represents a pathway to AI expertise, not just text processing. Some concrete examples:
A robot in an industrial plant can “test” millions of trials on a digital twin generated by a world model before acting in real.
Autonomous vehicles training in varied virtual environments to capture rare situations that in the real world would be costly or dangerous.
Creation of worlds for education, virtual reality, and urban planning, where AI simulates “what if…” with multiple variables.
And from AGI’s point of view, the combination of language + world could lead to agents that not only interpret what they are told, but also simulate what happens, act accordingly, and learn from the experience. This convergence is what many see as the next big step.
Some critical reservations:
- Although the technology is promising, there is still a gap between “world generation” and “intelligent agents within those worlds”. It is not enough to generate beautiful 3D scenes; AI must interact, reason, plan, and learn.
Computational costs, simulation quality, and fidelity to real physics remain barriers.
Integration with real processes (industrial, automotive, robotics) involves challenges: sensors, actuators and real/simulated hybrid environments.
There is a risk of overvaluation: that it will be presented as an “AGI solution” when, in fact, it is just one component of a much larger architecture.

Controllable world models like Marble represent a relevant evolution in AI: from “language only” to “world experience”. They do not compete with LLMs, but extend them: if LLMs taught machines to read and write, world models teach them to see, act, and simulate.
On the road to AGI, the convergence of language + world seems increasingly plausible as the architecture of the future.
What do you think?
-
Do you think world models like Marble represent the right path to truly intelligent AI?
-
Which industries do you think will be most impacted by the ability to simulate complex environments with AI?
-
Do you see direct applicability of these technologies in your industry or business?
-
Can you imagine collaborating with an AI in a 3D environment to design, plan or train processes?
-
How would you combine the power of language and simulation to solve a real problem?
Leave me your comments, ideas or even use cases you can think of. I am very interested in how you see this convergence between the text and the world, between prediction and experience. Let’s talk!
SOURCES


