

DeepSeek ha logrado alcanzar el nivel de los mejores modelos de lenguaje del mundo, usando solo una fracción de los recursos que requieren. algo que parecía del todo imposible.
Este LLM, no solo compite con gigantes como GPT-4,Gemini o Claude, sino que obliga a estos a replantearse su propia estrategia.
Ya generé hace algún tiempo un contenido relacionado con este modelo de lenguaje, pero quería profundizar en algunos aspectos. DeepSeek no es otro modelo más. de hecho, en su lanzamiento, provocó caídas multimillonarias en las acciones de empresas tecnológicas establecidas.
En el contenido de hoy voy a intentar explicar, de forma sencilla , qué hace tan especial este modelo y con ejemplos reales, porque detrás de este modelo no solo hay innovación técnica, sino una mejora revolucionaria en eficiencia.
¿Cómo funcionan los modelos clásicos como GPT o Claude?
Antes de entender la revolución, hay que conocer el sistema que vino a desafiar.
Modelos como GPT-4 o Claude funcionan bajo una lógica densa: usan todos sus parámetros en cada predicción. Imagina que cada vez que escribes una palabra, un ejército de 100.000 millones de neuronas se activa para ayudarte. Suena potente, ¿verdad? Y lo es, pero también es terriblemente caro en energía, tiempo y dinero.
Además, estos modelos generan texto palabra por palabra, sin poder anticiparse ni acelerar el proceso. Cada nueva palabra es como dar un paso a ciegas. Esto limita la velocidad, aumenta el coste computacional y acorta el contexto que pueden manejar de una sola vez.
Es como tener un supercerebro que se agota con cada frase que escribe.
DeepSeek: una nueva forma de pensar (y de ahorrar)
DeepSeek rompe con ese enfoque clásico. No lo hace más grande, lo hace más inteligente. ¿Cómo? Con cuatro grandes ideas que lo convierten en un modelo mucho más eficiente y potente:
- Mixture of Experts (MoE): sólo trabajan los que hacen falta: Imagina una orquesta donde, para cada canción, solo tocan los músicos necesarios. Eso es DeepSeek. Tiene más de 600 mil millones de parámetros, pero en cada predicción activa solo un pequeño grupo de “expertos” especializados. ¿El resultado? Mucha menos energía y cálculo para generar cada token. Es como encender solo la luz de la habitación en la que estás, en lugar de toda la casa.
- Predicción multi-token: ver varios pasos por delante: Mientras los modelos tradicionales avanzan palabra a palabra, DeepSeek entrena para prever varias palabras de una vez. Así no solo responde más rápido, sino que construye frases más coherentes. Es como si en lugar de ir leyendo letra por letra, el modelo ya tuviera en mente el final de la frase que está escribiendo.
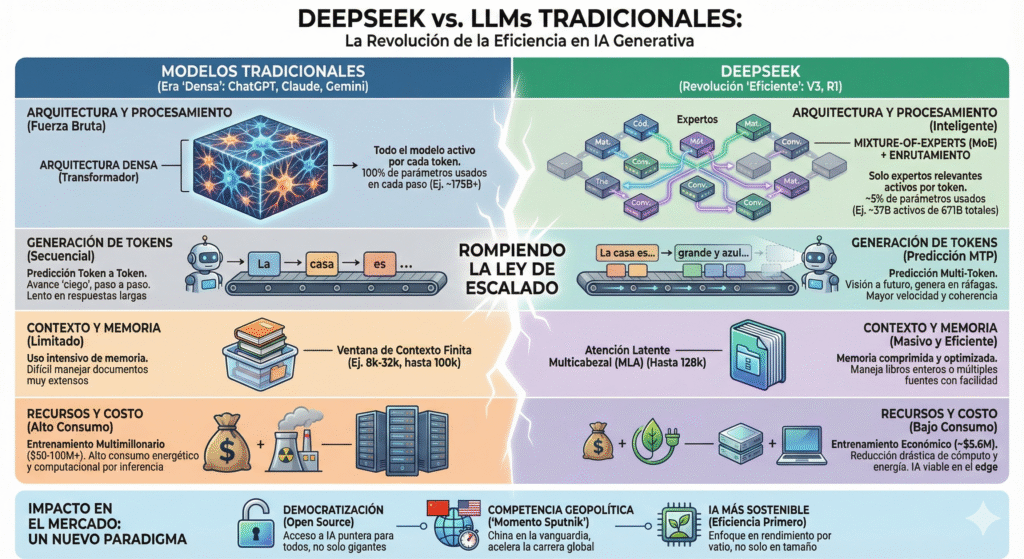
- Atención latente eficiente: memorizar más con menos: DeepSeek puede procesar hasta 128.000 tokens de contexto. Para que te hagas una idea, eso equivale a unas 200 páginas de texto. ¿Cómo lo hace sin explotar? Con una atención optimizada que condensa la información de forma más eficiente. Algo así como tener una memoria prodigiosa que ocupa menos espacio.
- Razonamiento encadenado (Chain-of-Thought) por defecto: Y no solo escribe rápido: piensa mejor. DeepSeek R1, su versión especializada en razonamiento, fue entrenada para mostrar su “paso a paso” interno antes de dar una respuesta. Esto mejora su lógica y precisión, especialmente en tareas complejas como matemáticas, programación o deducción.
Más con menos: ahorro brutal en energía y cómputo
Todo esto no es solo teoría. DeepSeek logró entrenarse con solo 5.6 millones de dólares, cuando modelos equivalentes requerían entre 50 y 100 millones de dólares Y durante el uso diario, solo activa un pequeño porcentaje de su red. ¿Te imaginas reducir un 80% el consumo de energía por cada respuesta sin perder calidad? Eso es lo que hace DeepSeek.
Y no solo eso: esta eficiencia permite ejecutar versiones más ligeras del modelo en portátiles o dispositivos locales, sin depender de grandes centros de datos. Esto democratiza el acceso a la IA potente, la hace más sostenible y reduce la dependencia de la nube.
Gracias a su arquitectura modular, su anticipación, y su forma de razonar, DeepSeek ha demostrado que no es necesario construir una IA más grande, sino una más inteligente y eficiente. Sin duda, abre la puerta a una nueva generación de modelos. Sin duda, esto ayudará a democratizar el uso de los modelos de lenguaje.
DeepSeek es un cambio de paradigma que demuestra que esto es posible. Y en tu caso. ¿Qué opinas del papel de China en esta nueva carrera tecnológica?¿Te ha sorprendido DeepSeek tanto como a mí? ¿Te gustaría usar una IA de este tipo desde tu propio ordenador, sin depender de la nube?Déjame tus comentarios; me encantará leerte.¡Buena semana!
Déjame tus comentarios, me encantará leerte.
¡Buena semana!


