

DeepSeek has managed to reach the level of the world’s best language models, using only a fraction of the resources they require, something that seemed quite impossible.
This LLM not only competes with giants such as GPT-4, Gemini, or Claude, but also forces them to rethink their own strategy.
I already generated some content related to this language model some time ago, but I wanted to go deeper into some aspects. DeepSeek is not just another model. In fact, at its launch, it caused multi-million dollar drops in the shares of established technology companies.
In today’s content I will try to explain, in a simple way, what makes this model so special and with real examples, because behind this model there is not only technical innovation, but also a revolutionary improvement in efficiency.
How do classic models such as GPT or Claude work?
Before understanding the revolution, it is necessary to know the system it came to challenge.
Models such as GPT-4 and Claude operate under a dense logic: they use all their parameters in every prediction. Imagine that every time you write a word, an army of 100 billion neurons is activated to help you. Sounds powerful, doesn’t it? It is, but it is also highly energy-intensive, time-consuming, and costly.
In addition, these models generate text word by word, without being able to anticipate or speed up the process. Each new word is like taking a blind step. This limits speed, increases computational cost, and shortens the context they can handle at once.
It’s like having a superbrain that gets exhausted with every sentence you write.
DeepSeek: a new way of thinking (and saving)
DeepSeek breaks with that classic approach. It doesn’t make it bigger; it makes it smarter. How? With four big ideas that make it a much more efficient and powerful model:
- Mixture of Experts (MoE): only the right people work. Imagine an orchestra where, for each song, only the necessary musicians play. That is DeepSeek. It has more than 600 billion parameters, but only a small group of specialized “experts” is active in each prediction. The result? Much less energy and computation are required to generate each token. It’s like turning on just the light in the room you’re in, instead of the whole house.
- Multi-token prediction: see several steps ahead. While traditional models advance word by word, DeepSeek is trained to predict multiple words at once. So it not only responds faster, but builds more coherent sentences. It is as if, instead of reading letter by letter, the model already has the end of the sentence it is writing in mind.
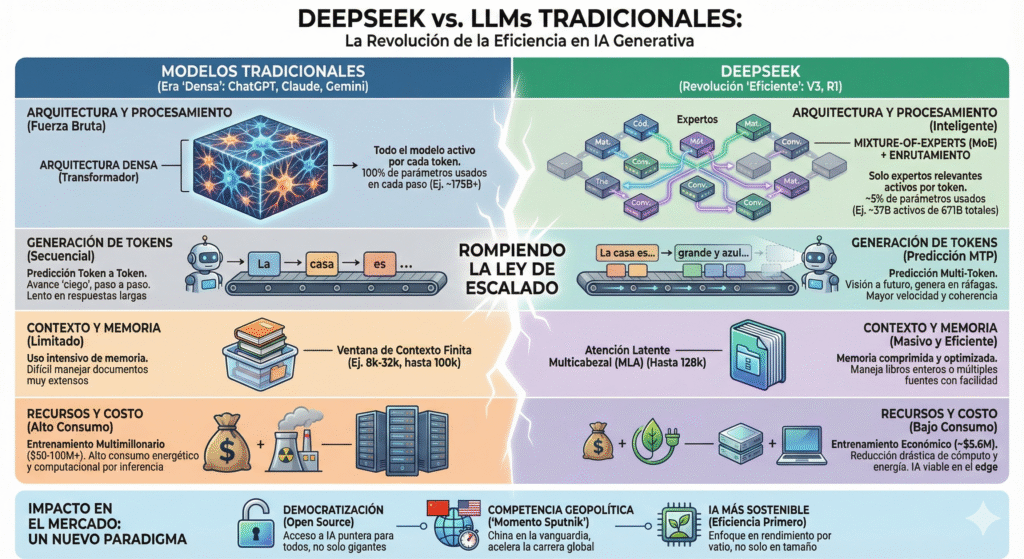
- Efficient latent attention: memorizing more with less: DeepSeek can process up to 128,000 context tokens. To give you an idea, that’s the equivalent of about 200 pages of text. How do you do it without exploding? With optimized attention that condenses information more efficiently. It’s like having a prodigious memory that takes up less space.
- Chain-of-Thought reasoning by default: And it doesn’t just type fast: it thinks better. DeepSeek R1, its specialized reasoning version, was trained to display its internal “step-by-step” before giving an answer. This improves its logic and accuracy, especially in complex tasks such as mathematics, programming or deduction.
More with less: brutal energy and computational savings
All this is not just theory. DeepSeek managed to train with only 5.6 million dollars, when equivalent models required between 50 and 100 million dollars. During daily use, it activates only a small percentage of its network. Can you imagine reducing energy consumption by 80% per response without losing quality? That’s what DeepSeek does.
Not only that: this efficiency enables running lighter versions of the model on laptops or local devices without relying on large data centers. This democratizes access to powerful AI, makes it more sustainable, and reduces dependence on the cloud.
Thanks to its modular architecture, anticipation, and reasoning, DeepSeek has demonstrated that it is not necessary to build a larger AI, but rather a more intelligent and efficient one. It certainly opens the door to a new generation of models. It will undoubtedly help democratize the use of language models.
DeepSeek is a paradigm shift that shows that this is possible. What do you think of China’s role in this new technological race, have you been as surprised by DeepSeek as I have been, would you like to use such an AI from your own computer, without relying on the cloud, leave me your comments, I’d love to read them, have a good week!
Leave me your comments, I’d love to read them.
Have a good week!


